kmerDB: A database encompassing genomic and proteomic k-mers
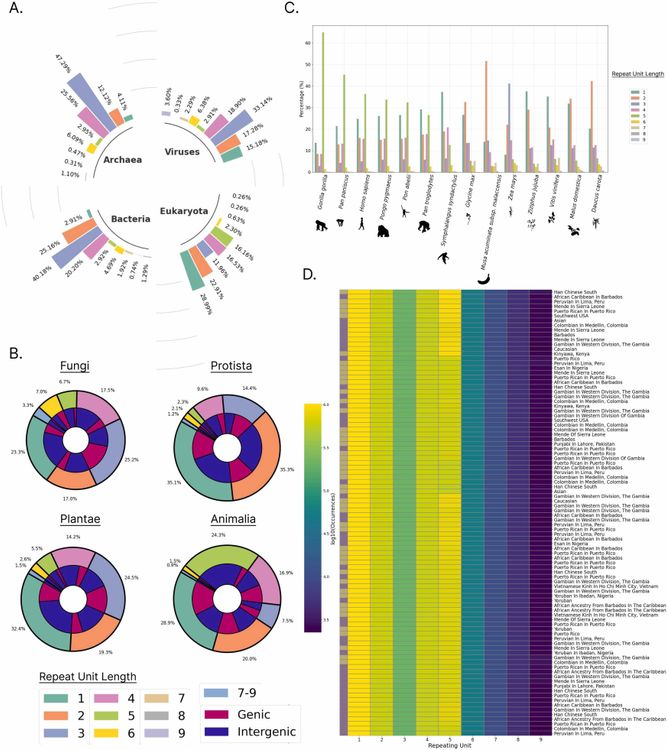
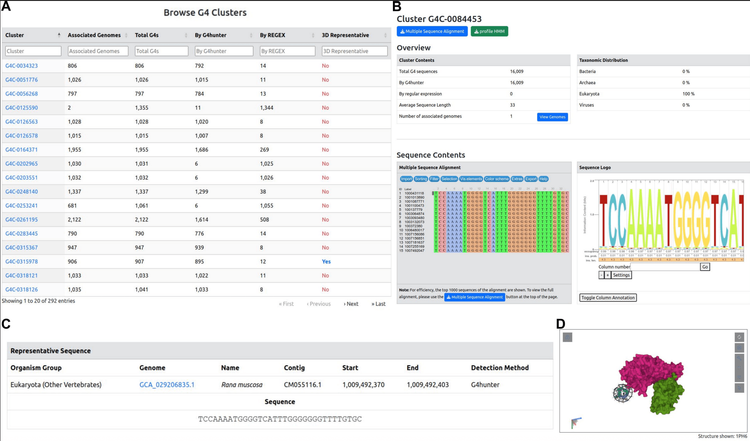
kmerDB is a database of genomic and proteomic k-mers, allowing researchers to analyze sub-sequences of DNA and proteins. K-mers are fundamental to bioinformatics, used in sequence alignment, genome assembly, motif discovery, and evolutionary analysis. This resource enables large-scale querying and cross-species comparisons.
Keywords
- k-mers
- genomics
- proteomics
- bioinformatics
Highlights
- Includes both DNA and peptide k-mers
- Supports motif discovery and functional associations
- Useful for metagenomics and proteomics
- Provides a unified k-mer search framework
Scale & coverage
- Billions of k-mer entries (not explicitly specified)